Global AI inference on managed infrastructure
Build and deploy intelligent applications that run AI models close to your users — at any scale.






























Built-in reliability
Distributed architecture with automatic failover keeps your AI running.
OpenAI-compatible API
Keep your existing code and SDKs — just change the endpoint.
Pay for usage
You pay only when your models are running inference.
Deploy from your local environment
Build, debug, and ship AI workloads the way you already code, but with the scale of distributed infrastructure.
Low-latency Instant Deploy Zero Config Pay Per Request
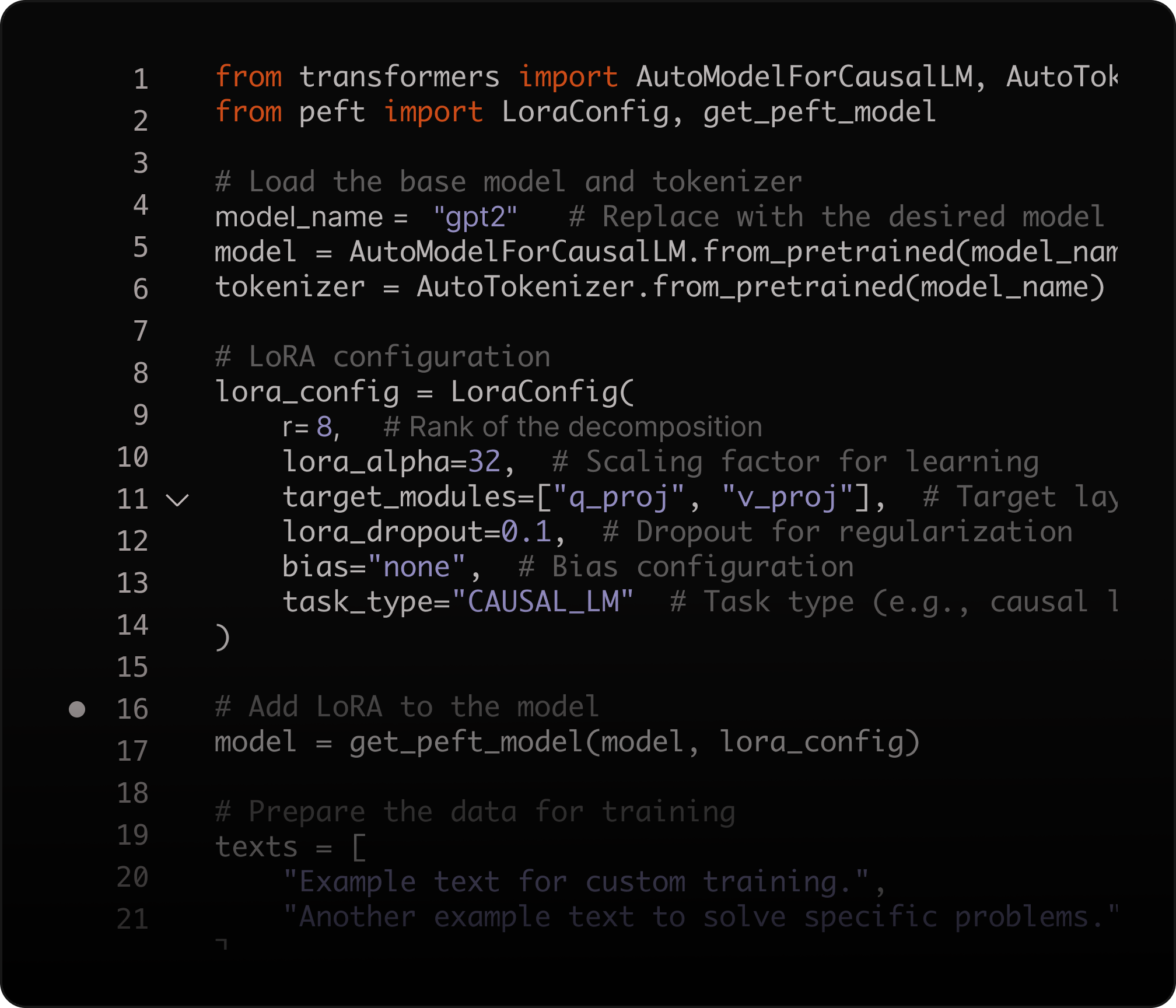
Fine-tune with LoRA
Adapt model outputs to your domain using Low-Rank Adaptation (LoRA), improving accuracy for specialized tasks while reducing compute costs—without full model retraining.
Learn more
Explore our Featured Models
From hello world to production AI workloads
Build AI applications with the same workflow you use for modern web apps. AI Inference connects with SQL Database, Object Storage, and Functions so teams can run models, retrieve context, store assets, and execute distributed logic in one platform.
Docs
What you can build with AI Inference

"With Azion, we scale proprietary AI models without managing infrastructure—inspecting millions of websites daily and automating the market’s fastest threat takedown."
Fabio Ramos
CEO
Primitives that Scale with You
Frequently Asked Questions
What is Azion AI Inference?
Azion AI Inference is a serverless platform for deploying and running AI models on a distributed architecture. It provides an OpenAI-compatible API for easy migration, supports LLMs, VLMs, embeddings, and reranking models, and offers LoRA fine-tuning for domain customization. Scale automatically without GPU management while maintaining low-latency responses globally.
Which models can I run?
Choose from a catalog of open-source models for text and code generation, vision-language tasks, embeddings, and reranking. The catalog evolves as new models become available, and you can fine-tune supported models with LoRA for your specific domain.
Is it compatible with OpenAI API?
Yes. AI Inference uses an OpenAI-compatible API format, so you can migrate existing applications by updating the base URL and credentials. Keep your current SDKs and integration patterns—no code rewrite required.
Can I fine-tune models?
Yes. AI Inference supports LoRA (Low-Rank Adaptation) fine-tuning, allowing you to specialize models for your domain without full retraining. This reduces compute costs while improving accuracy for specific tasks like customer support, code generation, or domain-specific Q&A.
How do I build RAG and semantic search?
Use AI Inference with SQL Database Vector Search to store embeddings and retrieve relevant context for RAG applications. This built-in vector search means no separate vector database to manage—SQL and vectors in one service.
Can I build AI agents and tool-calling workflows?
Yes. AI Inference powers agent patterns like ReAct and tool-calling workflows when combined with Applications, Functions, and external APIs. Azion provides templates and guides for LangChain and LangGraph-based agent architectures.
How do I migrate from Cloudflare Workers AI?
Migration is straightforward due to OpenAI-compatible APIs on both platforms. Update your base URL to point to Azion AI Inference endpoints, migrate any LoRA adapters, and integrate with Azion Functions. If you use Cloudflare Vectorize, migrate to Azion SQL Database Vector Search for built-in vector storage.
How does pricing compare to other platforms?
AI Inference uses straightforward per-request pricing without abstract units like "neurons." You pay for inference requests based on model and token usage—no idle costs, no capacity commitments. This transparency makes cost forecasting predictable compared to neuron-based billing models.
How do I deploy AI inference into my application?
Create an AI Inference endpoint, then integrate it into your request flow using Applications and Functions. This adds AI capabilities to existing APIs and user experiences with distributed execution, managed scaling, and automatic failover.
Build once.Deploy everywhere.
Talk to our team of experts and start saving money