One region: global
- Ashburn
- Atlanta
- Chicago
- Dallas
- Denver
- Los Angeles
- Miami
- New York
- Phoenix
- San Jose
- Seattle
- Querétaro
Hyperconnection expressed in numbers
to reach anywhere in the Americas and Europe
ASNs directly connected to the Azion network
availability, guaranteed by SLA
Edge Locations worldwide
Azion’s robust connectivity strategy helps us deliver the best performance, availability, and resiliency to our customers.
Our highly distributed architecture includes edge nodes strategically located inside ISPs' (Internet Service Providers) last-mile networks and connectivity to multiple IXPs (Internet Exchange Points), private and public peerings, and Tier 1 transit providers around the world.
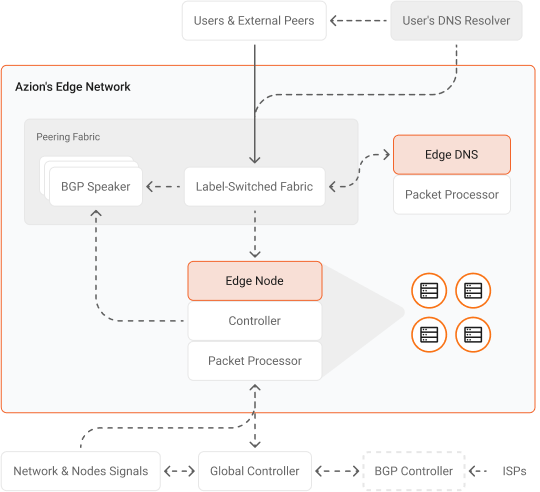
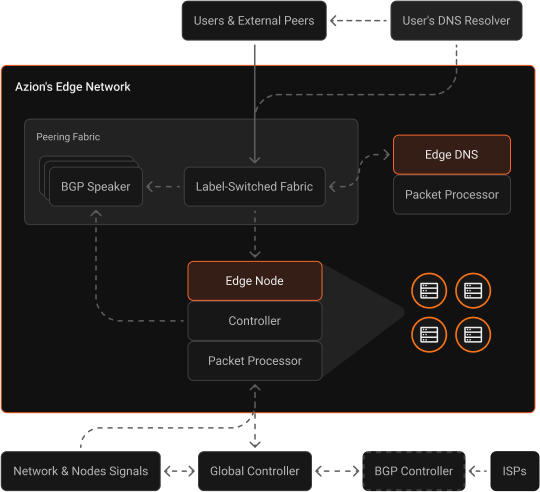
The network has DDoS protection at every edge location and is connected to multiple mitigation centers around the world, providing total reliability without impacting performance.
The mission to create a safer and more reliable Internet is a core value for us. To promote this, we are also working with other market players on the Internet Society's MANRS (Mutually Agreed Standards for Routing Security) initiative.


Azion Live Map
Discover e-commerce behavior in real time, the times with the most traffic or regions with the highest number of blocked attacks.
Sign-up and get $300 to use for 12 months.
Access to all products
No credit card required
Credit available to use for 12 months