

Azion Edge SQL fue diseñado pensando en los desafíos del desarrollo de aplicaciones modernas en las que las bases de datos relacionales son uno de los componentes clave.
¡Por supuesto que sabemos sobre estos desafíos! Consultar, procesar y gestionar datos siempre accediendo al origen, sufriendo problemas de desempeño causados por bases de datos centralizadas, alta latencia y otros problemas relacionados.
Es por ello que este nuevo producto necesitaba atender algunos requisitos para ser lo que planeamos como una solución ideal:
- Ser fácil de aprender y usar, empleando herramientas y lenguajes con los que los desarrolladores están familiarizados.
- Facilitar el despliegue de datos en las edge locations, aprovechando nuestra arquitectura distribuida globalmente.
- Ofrecer resiliencia, garantizando la integridad y disponibilidad de los datos.
- Minimizar el tiempo de transferencia y asegurar baja latencia para capacidad de respuesta en tiempo real.
- Ofrecer alta escalabilidad para diversos requisitos de almacenamiento.
- Y todo esto con replicación escalable y eficiente en recursos para garantizar costo-efectividad.
Después de meses de arduo trabajo, codificación y pruebas, estamos entusiasmados de profundizar y compartir con nuestra comunidad las complejidades del desarrollo de Edge SQL.
Conceptos básicos de Azion Edge SQL
Azion Edge SQL es una innovadora solución SQL para entornos de edge computing. Opera directamente en el edge, aprovechando el poder de las capacidades de edge computing para bases de datos relacionales serverless. Este enfoque permite que se acceda desde cualquier edge location, facilitando el procesamiento en tiempo real y el análisis de datos directamente en la red distribuida de Azion. En consecuencia, no hay necesidad de enrutar consultas a un servidor centralizado, lo que mejora el desempeño y reduce la latencia.
Al aprovechar el dialecto SQLite, Azion Edge SQL ofrece un entorno familiar para que los desarrolladores consulten y manipulen datos sin esfuerzo. Este enfoque se integra con los sistemas existentes, permitiendo a los desarrolladores aprovechar sus recursos de manera eficiente.
En nuestro esfuerzo por brindar una gran experiencia de usuario, también priorizamos la creación de un flujo de trabajo simplificado. De forma general, para operaciones de escritura, Azion Edge SQL opera de la siguiente manera:
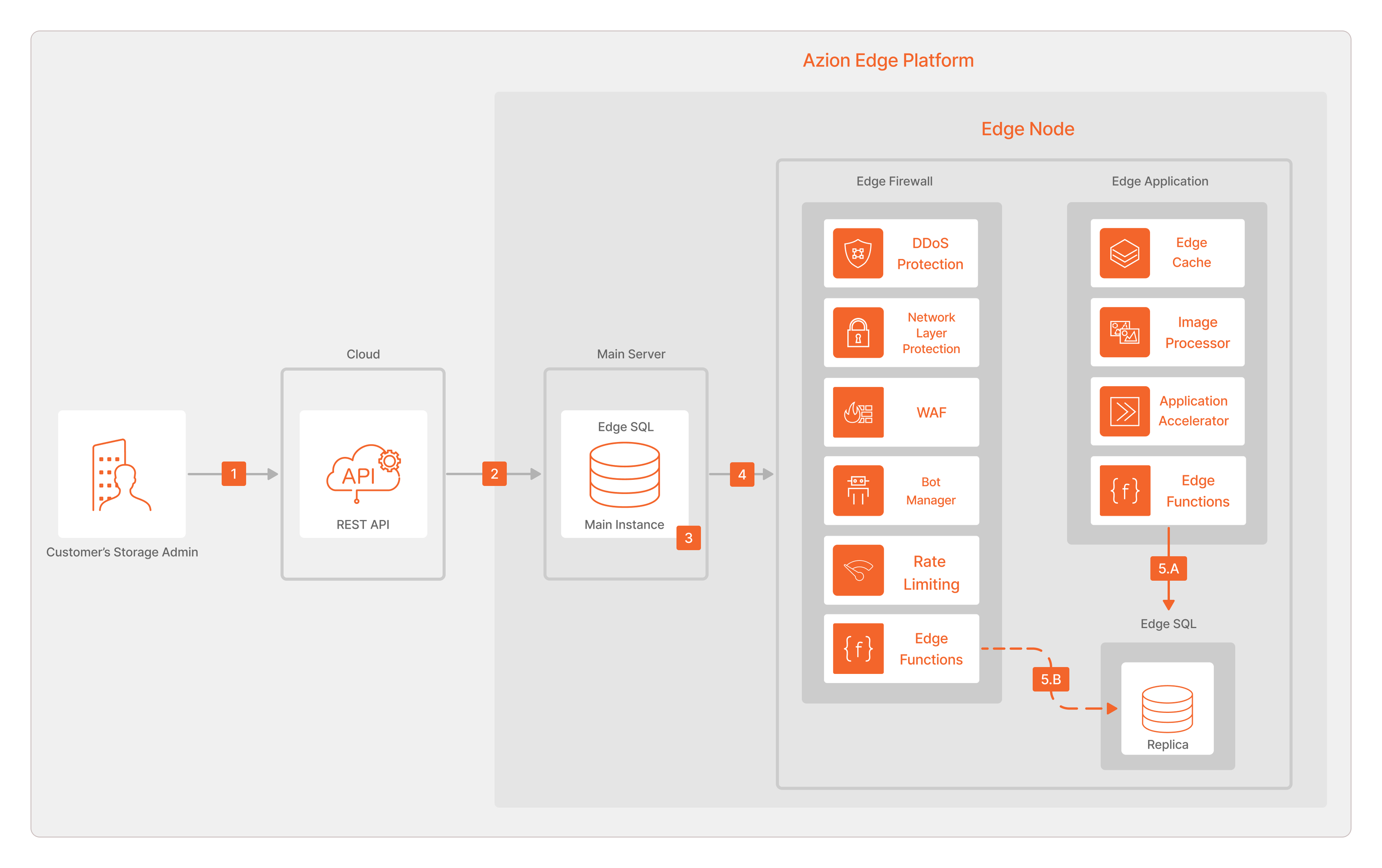
- El cliente establece una conexión a través de la REST API de Azion.
- Las operaciones se dirigen automáticamente a la Main Instance.
- La Main Instance realiza las operaciones y se generan cambios incrementales.
- Ocurre la replicación asíncrona de datos desde la base de datos principal a los Edge SQL Nodes.
- A. Las Réplicas guardan los cambios en los datos. Esto mantiene la base de datos actualizada, garantizando la consistencia eventual. B. También es posible guardar datos en la Réplica de la base de datos Edge SQL utilizando las Edge Functions de Edge Firewall.
Para comprender mejor el proceso, aquí está una explicación de algunos términos clave de Edge SQL:
- Main Instance: esta es la instancia principal de la base de datos implementada en el núcleo de la plataforma. Maneja las operaciones DDL (Data Definition Language) y DML (Data Manipulation Language) ejecutadas por los clientes. Las actualizaciones de la base de datos se transforman en snapshots incrementales, capturando los cambios realizados en los datos. Estos snapshots se envían luego a las Réplicas, asegurando que todas las edge locations tengan acceso a los últimos cambios de datos.
- Réplicas de Edge SQL: cada edge location recibe estos snapshots incrementales y los fusiona en sus respectivas Réplicas de Edge SQL.
- Replicación Global: replicar cambios en todas las edge locations con orden y completitud garantizados a escala global es un desafío significativo. Edge SQL lo aborda utilizando el Edge Orchestrator de Azion, que gestiona y controla eficientemente la distribución de contenido entre las edge locations.
- Réplicas de Lectura: en las edge locations, los cambios de la Main Instance se fusionan en las réplicas de lectura. Estas réplicas están disponibles para lectura a través de Cells Runtime y operan independientemente de las demás, brindando un entorno de alta disponibilidad para las aplicaciones. Esta independencia asegura que incluso si una réplica encuentra problemas o tiempo de inactividad, otras réplicas puedan continuar sirviendo datos, minimizando las interrupciones.
- Además, esta arquitectura automatiza las tareas de replicación, al distribuir eficientemente las actualizaciones y cambios de datos en las réplicas, optimiza el uso de recursos, reduce el tiempo de trabajo y, en última instancia, reduce los costos operativos.
Los clientes tienen dos opciones para interactuar con las bases de datos dentro del entorno Edge SQL:
- Edge SQL REST API: esta opción permite a los clientes ejecutar consultas DDL (Data Definition Language) y DML (Data Manipulation Language) directamente con la Main Instance. La REST API brinda una forma flexible y programática de interactuar con la base de datos, permitiendo una fácil integración en las aplicaciones existentes.
- Edge Functions: los clientes pueden acceder a la base de datos de réplica de solo lectura utilizando una edge function. Este acceso de solo lectura es útil para la recuperación de datos en tiempo real. Las edge functions brindan una forma ligera y eficiente de recuperar información de la base de datos.
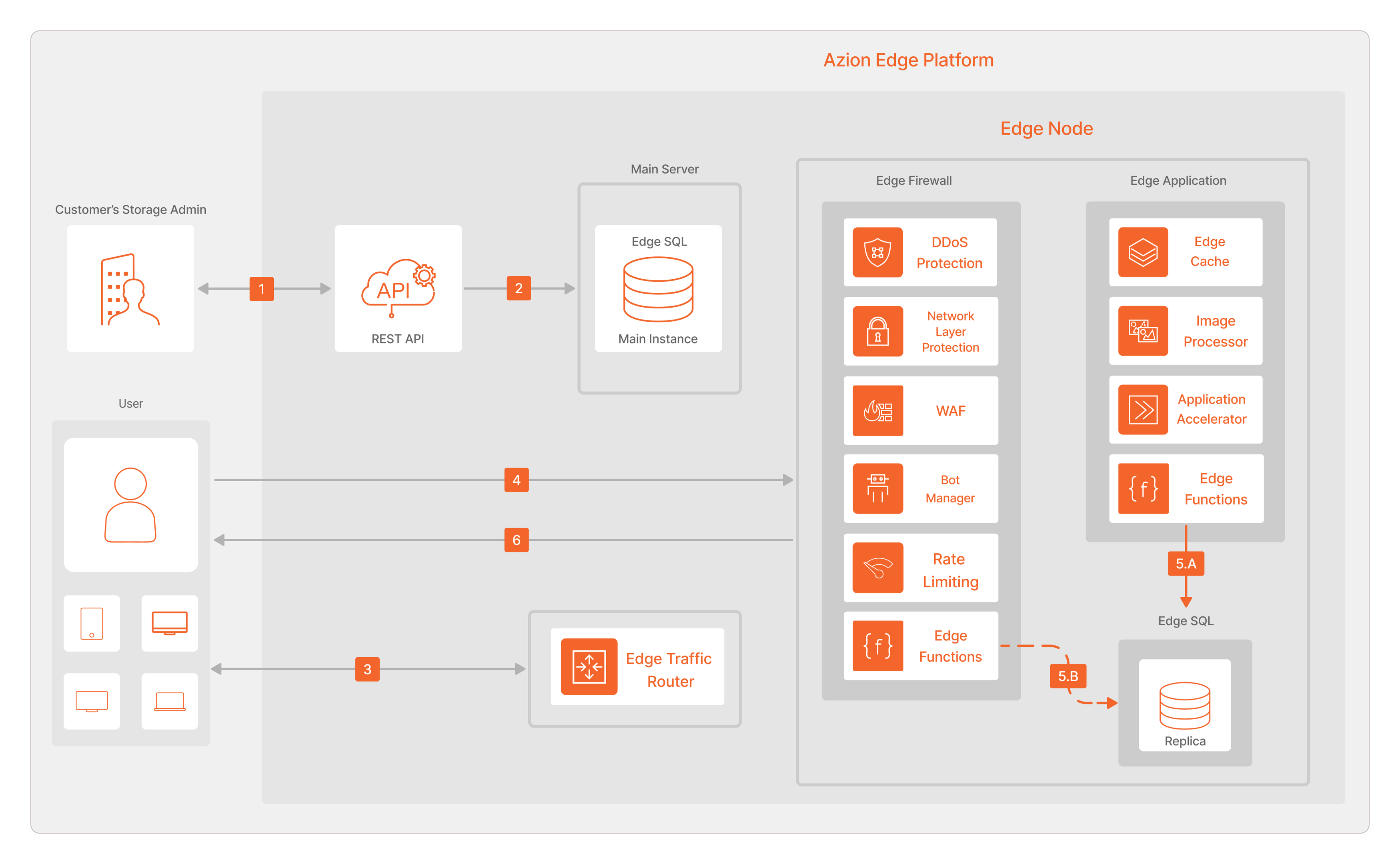
Para operaciones de lectura:
- El Customer’s Storage Admin inicia una operación de lectura en la Main Instance a través de la REST API.
- La REST API consulta los datos de la base de datos de la Main Instance y devuelve el resultado al Customer’s Storage Admin.
- El usuario, a través de una application, inicia una operación de lectura en el Edge Node utilizando Edge Functions. El Edge Traffic Router recibe la resolución DNS e indica el Edge Node más adecuado para ser consultado.
- La solicitud se envía al Edge Node más adecuado.
- A. Las Edge Functions de Edge Application, en cada Edge Node, son responsables de leer la Réplica. B. También es posible leer la Réplica de la base de datos Edge SQL utilizando las Edge Functions de Edge Firewall.
- Las Edge Functions entregan el resultado de la operación de lectura de vuelta al usuario.
Lee más sobre cómo crear tablas y gestionar bases de datos con Edge SQL.
¿Por qué usar Edge Functions para Edge SQL?
Azion Edge Runtime proporciona un conjunto de recursos para desarrollar en un contexto de edge, incluyendo edge functions basadas en JavaScript para implementar lógica de negocio. Entonces, teniendo poderosas herramientas propias, decidimos usarlas y aprovecharlas al máximo.
En el contexto de Edge SQL, las Edge Functions de Azion pueden acceder a las réplicas de lectura, promoviendo una forma de recuperar datos sin latencia de red. Este enfoque mejora el desempeño para las aplicaciones de usuario:
- Mayor desempeño: al distribuir la carga en múltiples edge locations, las edge functions mejoran el desempeño. Esta arquitectura distribuida asegura que las solicitudes de recuperación de datos se manejen eficientemente, incluso durante períodos de alta demanda.
- Latencia ultra baja: dado que no hay necesidad de acceder a la base de datos de origen para operaciones de solo lectura, la recuperación de datos a través de edge functions experimenta una latencia ultra baja. Los usuarios se benefician de tiempos de respuesta más rápidos, mejorando la experiencia general del usuario y el desempeño de la aplicación.
Combinar el poder de las Edge Functions de Azion con réplicas de lectura te brinda un desempeño y capacidad de respuesta óptimos para tus aplicaciones, al tiempo que minimiza los problemas de latencia de red.
EdgeSQL ofrece una API de JavaScript fácil de usar para acceder a bases de datos, facilitando el rápido desarrollo de aplicaciones. Con EdgeSQL, no hay necesidad de conexiones a dispositivos de red externos para obtener datos de usuario.
Exploremos un ejemplo de edge function para ilustrar esto:
import { Database } from "azion:sql";
const validNameRegex = /^\[a-zA-Z0-9\_\]+$/;
const supportedActions = \['list', 'head'\];
async function execQuery(dbName, query, params) {
try {
const conn = await Database.open(dbName);
const rows = await conn.query(query, params);
return rows;
} catch (error) {
throw new Error(\`Database error: ${error.message}\`);
}
}
async function handleRequest(request) {
const { pathname } = new URL(request.url);
const pathParts = pathname.split('/').filter(Boolean);
// Thorough validation
if (
pathParts.length !== 3 ||
pathParts\[0\] !== 'api' ||
!validNameRegex.test(pathParts\[1\]) || // Validate dbName
!validNameRegex.test(pathParts\[2\]) || // Validate tableName
!supportedActions.includes(pathParts\[3\]) // Validate action
) {
return new Response("Invalid request", { status: 400 });
}
const \[\_, dbName, tableName, action\] = pathParts;
let query, params;
if (action === 'count') {
query = 'SELECT COUNT(\*) FROM ?';
params = \[tableName\];
} else if (action === 'head') {
query = 'SELECT \* FROM ? limit 10';
params = \[tableName\];
} else {
return new Response("Internal server error", { status: 500 });
}
try {
console.log(\`EdgeSQL: ${dbName}, ${tableName}, ${query}, ${params}\`);
const rows = await execQuery(dbName, query, params);
if (request.headers.get('Accept') === 'application/json') {
return new Response(JSON.stringify(rows), {
headers: { 'Content-Type': 'application/json' },
});
} else {
return new Response("Only JSON format is currently supported", { status:
415 });
}
} catch (error) {
console.error(error);
return new Response("Internal server error", { status: 500 });
}
}
addEventListener("fetch", (event) =\>
event.respondWith(handleRequest(event.request)));
Este código configura una edge function serverless para manejar solicitudes HTTP para consultar una base de datos usando Azion EdgeSQL.
- La edge function comienza importando la clase de base de datos necesaria. La función
execQuerymaneja la conexión a la base de datos y ejecuta la consulta SQL, gestionando cualquier error potencial. - La función
handleRequestprocesa las solicitudes entrantes, las valida, construye la consulta SQL apropiada y usaexecQuerypara ejecutar la consulta. Devuelve los resultados en formato JSON o un error si la solicitud es inválida. - Finalmente, un
event listener for fetch eventsactiva la funciónhandleRequesten solicitudes HTTP.
En resumen, esta función edge maneja eficientemente las solicitudes HTTP para realizar consultas SQL en una base de datos EdgeSQL.
Puedes consultar la Edge SQL API para leer sobre las clases, métodos y atributos relacionados.
Consulta cómo interactuar con Edge SQL a través de Edge Functions, Edge SQL Shell, y CURL examples para escribir y consultar datos.
¿Cómo ocurre la Replicación Global?
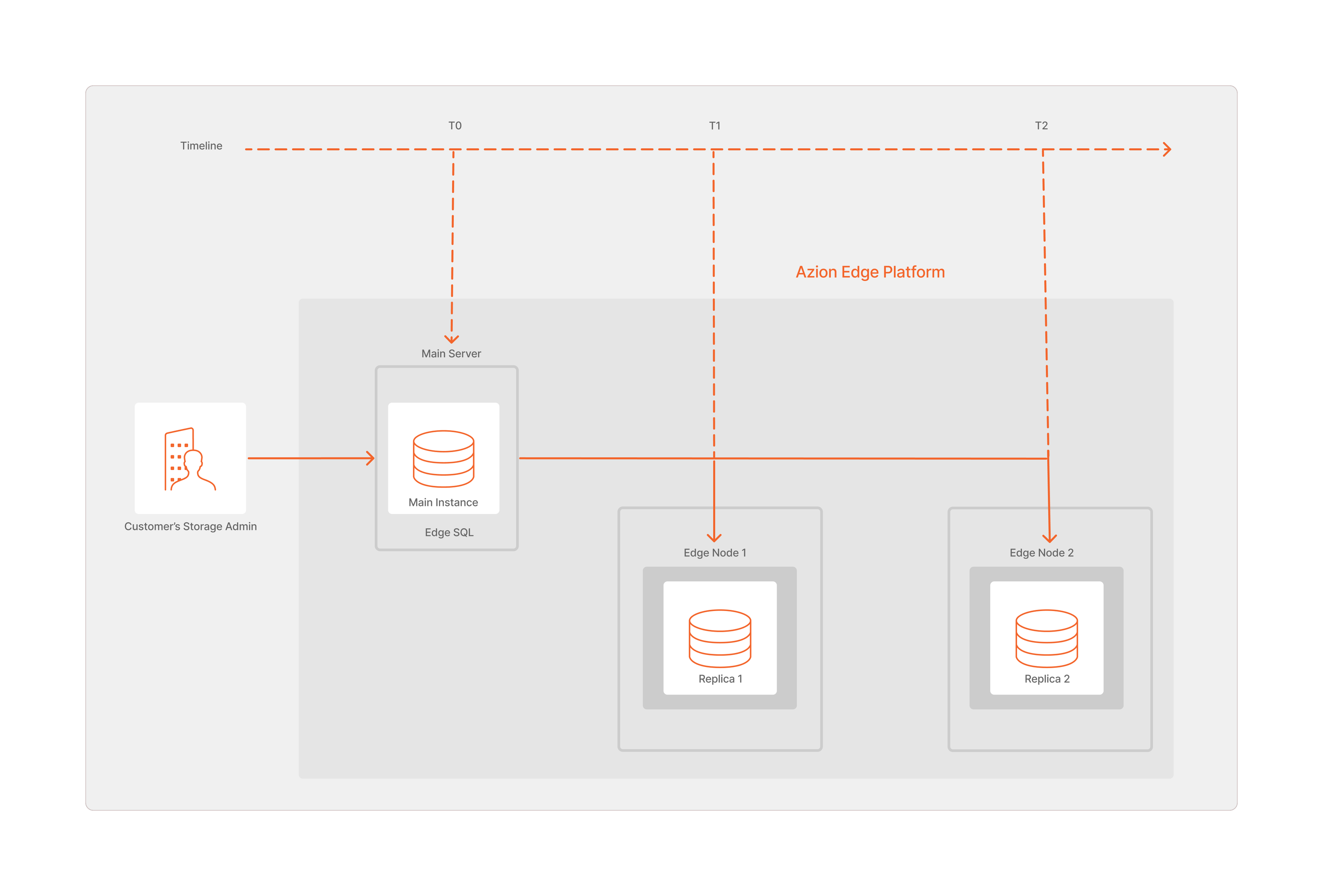
Para garantizar la disponibilidad y tolerancia a fallos de Edge SQL, las réplicas se distribuyen dentro de la Azion Edge Network para asegurar que toda la información se replique y almacene en todos los nodos deseados. Esta estrategia de replicación integral garantiza que los datos sean accesibles y estén actualizados cuando los usuarios accedan directamente a ellos en el edge, independientemente de su ubicación.
Para lograrlo, las operaciones ejecutadas en la base de datos de la Main Instance se empaquetan en archivos Write-Ahead Logging (WAL). Estos archivos WAL, junto con snapshots completos, se distribuyen luego a través de la red edge para garantizar la disponibilidad y consistencia de los datos en todas las edge locations.
- Los archivos WAL funcionan como registros de las operaciones ejecutadas para modificar los datos. Cada nuevo estado de datos se extrae a las réplicas. Este mecanismo garantiza la durabilidad, atomicidad y disponibilidad. El servicio de distribución entrega todos los incrementos y permite la recuperación de la base de datos en cada edge location.
- Una vez que los archivos WAL están disponibles en cada edge location, el servicio de merge asegura que los incrementos se guarden en el orden correcto, realizando la actualización de cada réplica.
En este contexto, Azion Edge Orchestrator recibe los archivos WAL y snapshots generados desde la Main Instance, ejecuta una replicación de lectura asíncrona y luego replica los datos en las edge locations.
Dado que las actualizaciones son asíncronas, existe la posibilidad de que la réplica de lectura se retrase con respecto al estado actual de la Main Instance. Este retraso, conocido como replica lag, representa la diferencia entre la Main Instance y una réplica de lectura. Es importante tener en cuenta que pueden existir múltiples réplicas de lectura, cada una potencialmente experimentando diferentes grados de retraso.
Sobre modelos de consistencia
Cuando se inicia una transacción en la Main Instance, la vista que recibe la transacción se “congela” en el tiempo. Cualquier operación de escritura realizada por una transacción es inmediatamente visible para sí misma, pero completamente aislada de cualquier otra transacción en curso. Esto garantiza que EdgeSQL proporcione transacciones serializables, manteniendo una vista consistente y aislada de la base de datos para cada transacción.
Aislamiento de snapshots en modo WAL
Utilizando el aislamiento de snapshots, los cambios se registran en los archivos WAL, mientras que las operaciones se implementan en el orden en que se ejecutaron en la Main Instance. Esto proporciona una vista consistente y predecible de la base de datos para cada transacción, incluso en presencia de modificaciones concurrentes. Los snapshots son la base para propagar los cambios a las réplicas de lectura y promover la consistencia global eventual de la base de datos distribuida.
¿Qué sucede con la Consistencia Global Eventual?
Los desarrolladores y especialistas en datos están familiarizados con el Teorema CAP. Según el teorema, es imposible garantizar simultáneamente Consistencia, Disponibilidad y Tolerancia a Particiones en un sistema distribuido. Durante el desarrollo de Edge SQL, fue una preocupación cómo manejar esta situación.
La disponibilidad de datos y la tolerancia a particiones se garantizan a través de la red distribuida, la replicación de lectura, la orquestación y el mecanismo de failover. Precisamente, el uso de archivos WAL y aislamiento de snapshots nos ayuda en este asunto. Los archivos WAL garantizan la durabilidad al registrar los cambios antes de que se apliquen a la base de datos, lo que ayuda a recuperar datos en caso de fallas mientras se mantiene la consistencia. Mientras tanto, el aislamiento de snapshots garantiza que las transacciones concurrentes no interfieran entre sí, preservando así la consistencia.
Esto hace que la consistencia sea la candidata para el trade-off. Sin embargo, la consistencia eventual fue la respuesta para nosotros en este tema, teniendo los medios para garantizar que los datos eventualmente se vuelvan consistentes en todas las ubicaciones.
Utilizando la Consistencia Eventual como enfoque, podemos asegurar que las actualizaciones realizadas en la Main Instance se repliquen gradualmente en las edge locations, logrando consistencia a lo largo del tiempo. Este enfoque también reduce la latencia en las operaciones de lectura, porque la lectura de datos no depende de la sincronización entre réplicas.
Read Committed
Las réplicas de lectura solo reciben datos confirmados, asegurando que los datos accesibles a través del entorno de runtime sigan el modelo de read committed.
¿Están seguros mis datos?
Trabajar con datos, especialmente datos confidenciales, exige los más altos estándares y prácticas para garantizar la seguridad de los datos. La forma en que funciona Edge SQL y cómo fue concebido facilita esta tarea.
La distribución global de los archivos de Write-Ahead Logging (WAL) utilizando Edge Orchestrator garantiza el uso de técnicas modernas de gestión de datos en entornos distribuidos, como Edge SQL. Para garantizar la distribución segura y la verificación de integridad de los datos, se emplean técnicas sofisticadas. Estas técnicas incluyen protocolos de encriptación, firmas digitales y checksums, entre otras, para salvaguardar los datos durante la transmisión y el almacenamiento.
Además, la garantía de entrega de datos es primordial, lograda a través de robustas estrategias de replicación de datos, arquitecturas tolerantes a fallas y mecanismos de monitoreo. Estas medidas preservan colectivamente la confiabilidad, consistencia y disponibilidad de los datos en ubicaciones geográficamente dispersas.
Al proporcionar aislamiento en tiempo de ejecución, el entorno de ejecución de la base de datos también es seguro, previniendo el acceso no autorizado y la manipulación de datos confidenciales. El aislamiento en tiempo de ejecución también garantiza el aislamiento de recursos, previniendo la contención de recursos y los ataques de denegación de servicio (DoS). Cada instancia de base de datos se ejecuta en un entorno aislado, asegurando que tenga recursos dedicados y no pueda afectar negativamente a otros procesos en el sistema.
Además, al utilizar la Plataforma de Edge Computing de Azion, los datos están protegidos por los productos Azion Secure, incluidos DDoS Protection y Web Application Firewall, para aumentar la seguridad de tus datos.
Edge SQL en la práctica
¿Buscas inspiración sobre cómo usar Azion Edge SQL en la práctica? En una frase: este producto agiliza las consultas y operaciones de bases de datos en el edge. Sin embargo, ya hemos identificado algunos casos de uso de los cuales nuestros clientes y el equipo se están beneficiando, o podrían comenzar a implementar ahora que está disponible:
- Seguimiento de pedidos: rastrea pedidos, gestiona los estados de entrega y proporciona actualizaciones en tiempo real a los clientes.
- Detección de fraudes: detecta y previene actividades fraudulentas rápidamente analizando datos en tiempo real con Edge SQL.
- Personalización: ofrece recomendaciones personalizadas basadas en el comportamiento del usuario.
- Precios en tiempo real: actualiza los precios de los productos en tiempo real según las condiciones del mercado.
- Resiliencia: minimiza el tiempo de inactividad, previene pérdidas y garantiza la resiliencia en aplicaciones críticas con réplicas de bases de datos Edge Node.
- Simplificación de microservicios: aprovecha los microservicios, garantizando consistencia y simplificando la capa de datos en arquitecturas serverless.
Azion Edge SQL está disponible en Preview. Conoce más sobre cómo comenzar a usarlo en la documentación.





