

Azion Edge SQL was designed thinking of the challenges of developing modern applications in which relational databases are one of the key components.
Yeah, we know about it! Querying, processing, and managing data always accessing the origin, and suffering from performance issues caused by centralized databases, high latency, and other related issues.
For this matter, this new product needed to attend to some requirements to be what we were planning as an ideal solution:
- Be easy to learn and use, employing tools and languages developers are familiar with.
- Facilitate the deployment of data at the edge locations, leveraging our globally distributed architecture.
- Offer resilience, ensuring data integrity and availability.
- Minimize transfer time and assure low latency for real-time responsiveness.
- Provide high scalability for diverse storage requirements.
- And all this with scalable, resource-efficient replication to guarantee cost-effectiveness.
After months of hard work, coding, and testing, we are thrilled to delve deeper into and share with our community the intricacies of developing Edge SQL.
The Basics of Azion Edge SQL
Azion Edge SQL is an innovative SQL solution for edge computing environments. It operates directly at the edge, leveraging the power of edge computing capabilities to serverless relational databases. This approach allows it to be accessed from any edge location, facilitating real-time processing and data analysis directly on Azion’s distributed network. Consequently, there’s no need to route queries to a centralized server, enhancing performance and reducing latency.
By leveraging SQLite’s dialect, Azion Edge SQL offers a familiar environment for developers to query and manipulate data effortlessly. This approach integrates with existing systems, empowering developers to harness its capabilities efficiently.
In our effort to provide a great user experience, we also prioritized creating a streamlined workflow. At a high level, for write operations, Azion Edge SQL operates as follows:
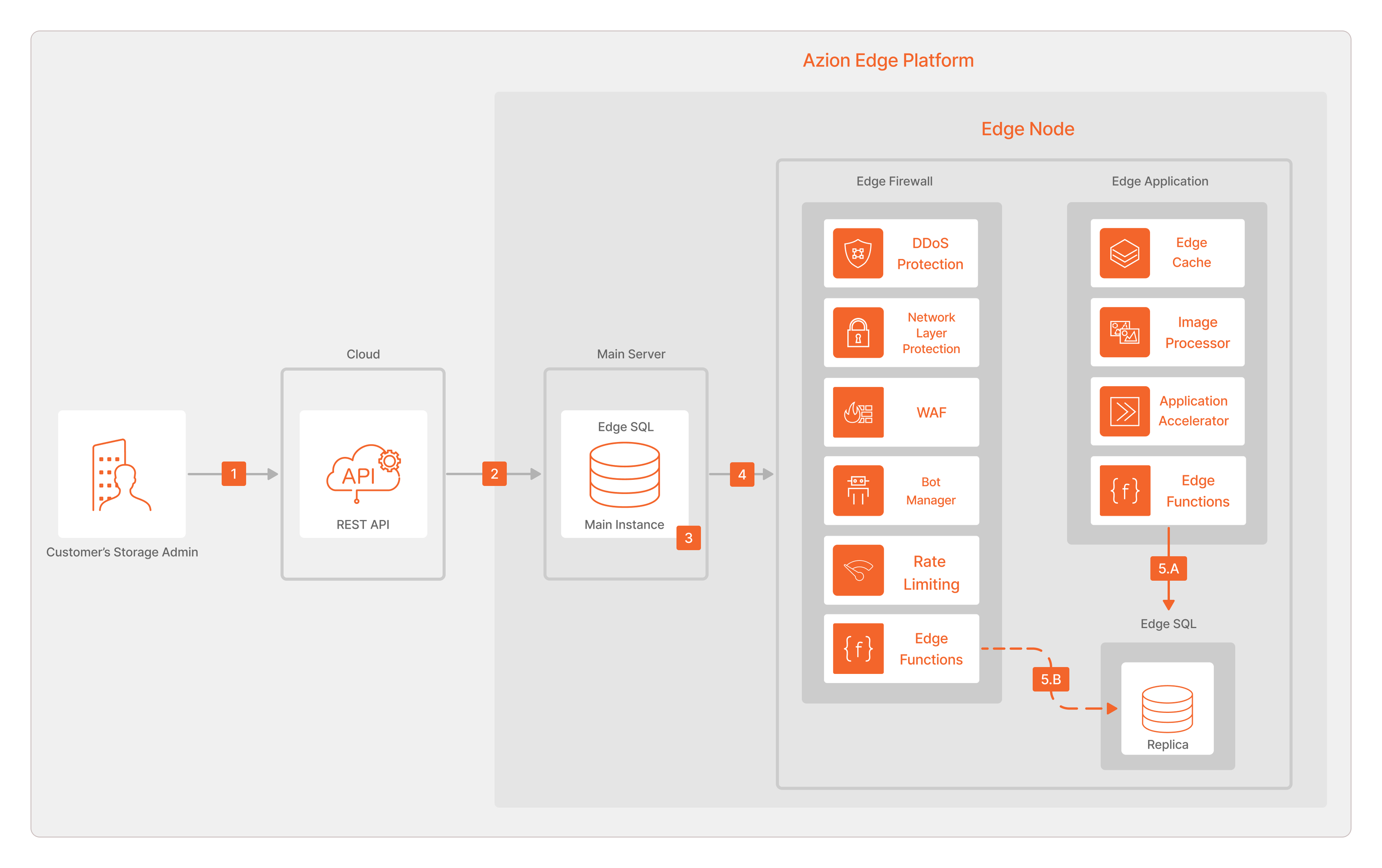
- The customer establishes a connection through Azion REST API.
- Operations are automatically targeted to the Main Instance.
- The Main Instance performs the operations and incremental changes are generated.
- Asynchronous Data Replication happens from the Main Database to the Edge SQL Nodes.
- A. The Replicas merge the data changes. This keeps the database up to date, guaranteeing eventual consistency. B. It’s also possible to merge data to the Edge SQL database Replica using the Edge Functions on Edge Firewall.
To understand better the process, here’s a breakdown of Edge SQL:
- Main Instance: this is the primary database instance deployed at the platform core. It handles DDL (Data Definition Language) and DML (Data Manipulation Language) operations executed by customers. The database updates are transformed into incremental snapshots, capturing changes made to the data. These snapshots are then pushed to the Replicas, ensuring that all edge locations can access to the latest data changes.
- Edge SQL Replicas: each edge location receives these incremental snapshots and merges them into their respective Edge SQL Replicas.
- Global Replication: replicating changes across all edge locations with guaranteed order and completeness on a global scale is a significant challenge. Edge SQL addresses it by utilizing Azion Edge Orchestrator which efficiently manages and controls content distribution among edge locations.
- Read Replicas: on the edge locations, the changes from the Main Instance are merged into the read replicas. These replicas are made available for reading via Cells Runtime and operate independently of the others, providing a high-availability environment for the applications. This independence ensures that even if one replica encounters issues or downtime, other replicas can continue serving data, minimizing disruptions.
- Furthermore, this architecture automates replication tasks, by efficiently distributing data updates and changes across replicas, it optimizes resource usage, reduces work time, and ultimately lowers operational costs.
Customers have two options for interacting with databases within the Edge SQL environment:
- Edge SQL REST API: this option enables customers to execute DDL (Data Definition Language) and DML (Data Manipulation Language) queries directly on the Main Instance. The REST API provides a flexible and programmatic way to interact with the database, allowing easy integration into existing applications.
- Edge Functions: customers can access the read-only replica database using an edge function. This read-only access is useful for real-time data retrieval. Edge functions provide a lightweight and efficient way to retrieve information from the database.
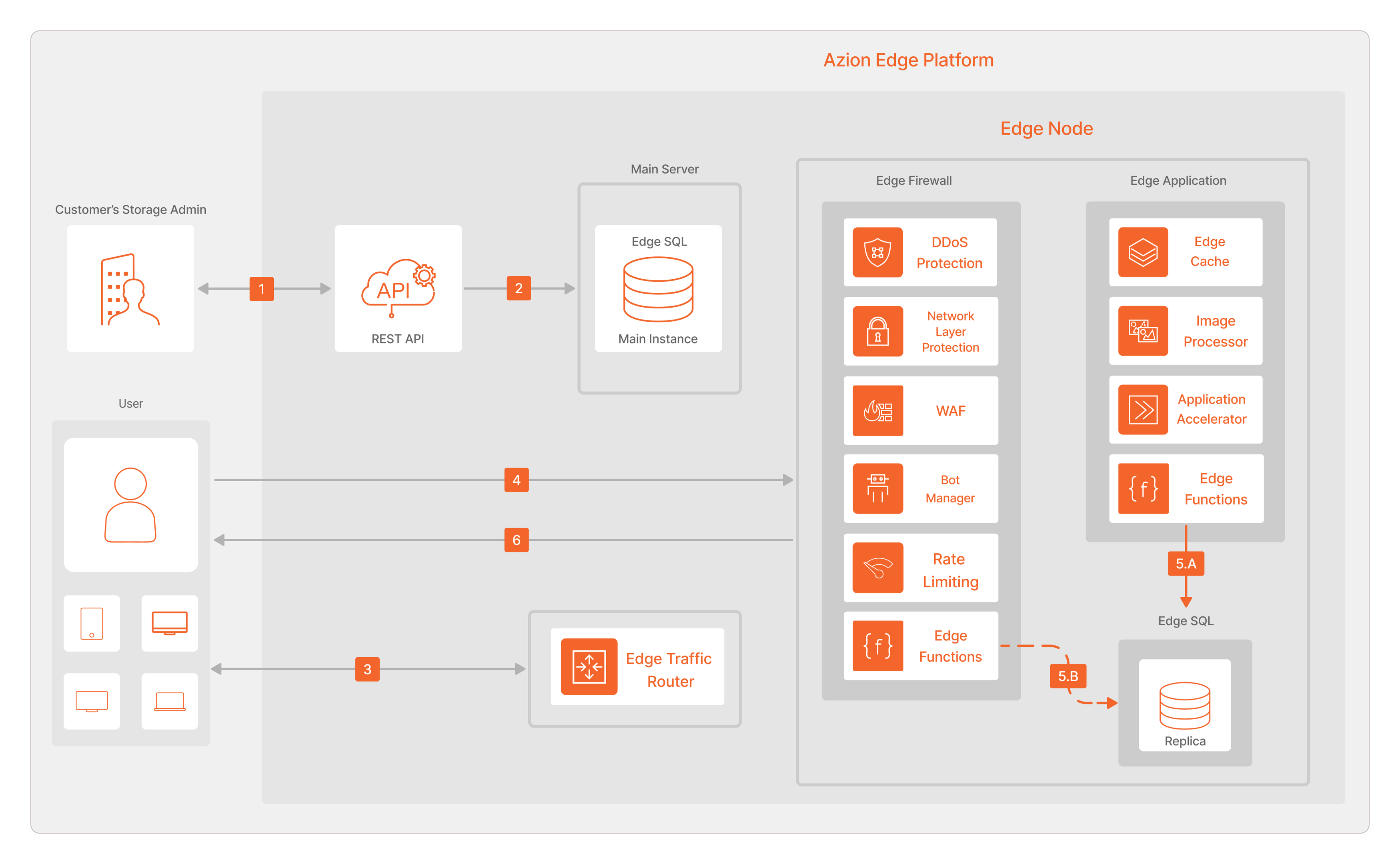
For reading operations:
- The Customer’s Storage Admin starts a reading operation on the Main Instance through the REST API.
- The REST API consults the Edge SQL Main Instance database data and returns the result to the Customer’s Storage Admin.
- The user, through an application, starts a reading operation on the Edge Node using Edge Functions. The Edge Traffic Router receives the DNS resolution and indicates the most adequate Edge Node to be consulted.
- The request is sent to the most adequate Edge Node.
- A. The Edge Functions on Edge Application, in each Edge Node, are responsible for reading the Replica. B. It’s also possible to read the Edge SQL database Replica using the Edge Functions on the Edge Firewall.
- The Edge Functions deliver the reading operation result back to the user.
Read more on how to create tables and manage databases with Edge SQL.
Why Edge Functions for Edge SQL?
Azion Edge Runtime provides a set of resources for developing in an edge context, including edge functions based on JavaScript to implement business logic. So, having powerful tools in-house, we decided to use them and make the most of them.
In the Edge SQL context, Azion Edge Functions can access the read-only replicas promoting a way to retrieve data without networking latency. That approach enhances performance for user applications:
- Increased throughput: by distributing the load across multiple edge locations, edge functions improve throughput. This distributed architecture ensures that data retrieval requests are efficiently handled, even during periods of high demand.
- Ultra-low latency: since there’s no need to access the origin database for read-only operations, data retrieval via edge functions experiences ultra-low latency. Users benefit from faster response times, enhancing the overall user experience and application performance.
Combining Azion Edge Functions’ power with read-only replicas gives you optimal performance and responsiveness for your applications while minimizing network latency issues.
Edge SQL offers an easy-to-use JavaScript API for accessing databases, facilitating rapid application development. With Edge SQL, there’s no need to make connections to external network devices to fetch user data.
Let’s explore an example edge function to illustrate this:
import { Database } from "azion:sql";
const validNameRegex = /^\[a-zA-Z0-9\_\]+$/;
const supportedActions = \['list', 'head'\];
async function execQuery(dbName, query, params) {
try {
const conn = await Database.open(dbName);
const rows = await conn.query(query, params);
return rows;
} catch (error) {
throw new Error(\`Database error: ${error.message}\`);
}
}
async function handleRequest(request) {
const { pathname } = new URL(request.url);
const pathParts = pathname.split('/').filter(Boolean);
// Thorough validation
if (
pathParts.length !== 3 ||
pathParts\[0\] !== 'api' ||
!validNameRegex.test(pathParts\[1\]) || // Validate dbName
!validNameRegex.test(pathParts\[2\]) || // Validate tableName
!supportedActions.includes(pathParts\[3\]) // Validate action
) {
return new Response("Invalid request", { status: 400 });
}
const \[\_, dbName, tableName, action\] = pathParts;
let query, params;
if (action === 'count') {
query = 'SELECT COUNT(\*) FROM ?';
params = \[tableName\];
} else if (action === 'head') {
query = 'SELECT \* FROM ? limit 10';
params = \[tableName\];
} else {
return new Response("Internal server error", { status: 500 });
}
try {
console.log(\`EdgeSQL: ${dbName}, ${tableName}, ${query}, ${params}\`);
const rows = await execQuery(dbName, query, params);
if (request.headers.get('Accept') === 'application/json') {
return new Response(JSON.stringify(rows), {
headers: { 'Content-Type': 'application/json' },
});
} else {
return new Response("Only JSON format is currently supported", { status:
415 });
}
} catch (error) {
console.error(error);
return new Response("Internal server error", { status: 500 });
}
}
addEventListener("fetch", (event) =\>
event.respondWith(handleRequest(event.request)));
This code sets up a serverless edge function to handle HTTP requests for querying a database using Azion EdgeSQL.
- The edge function begins by importing the necessary database class. The
execQueryfunction handles the database connection and executes the SQL query, managing any potential errors. - The
handleRequestfunction processes incoming requests, validates them, constructs the appropriate SQL query, and uses execQuery to run the query. It returns the results in JSON format or an error if the request is invalid. - Finally, an
event listener for fetch eventstriggers thehandleRequestfunction on HTTP requests.
In summary, this edge function efficiently handles HTTP requests to perform SQL queries on an EdgeSQL database.
You can consult the Edge SQL API to know classes, methods, and related attributes.
Check how to interact with Edge SQL through Edge Functions, Edge SQL Shell, and CURL examples to write and query data.
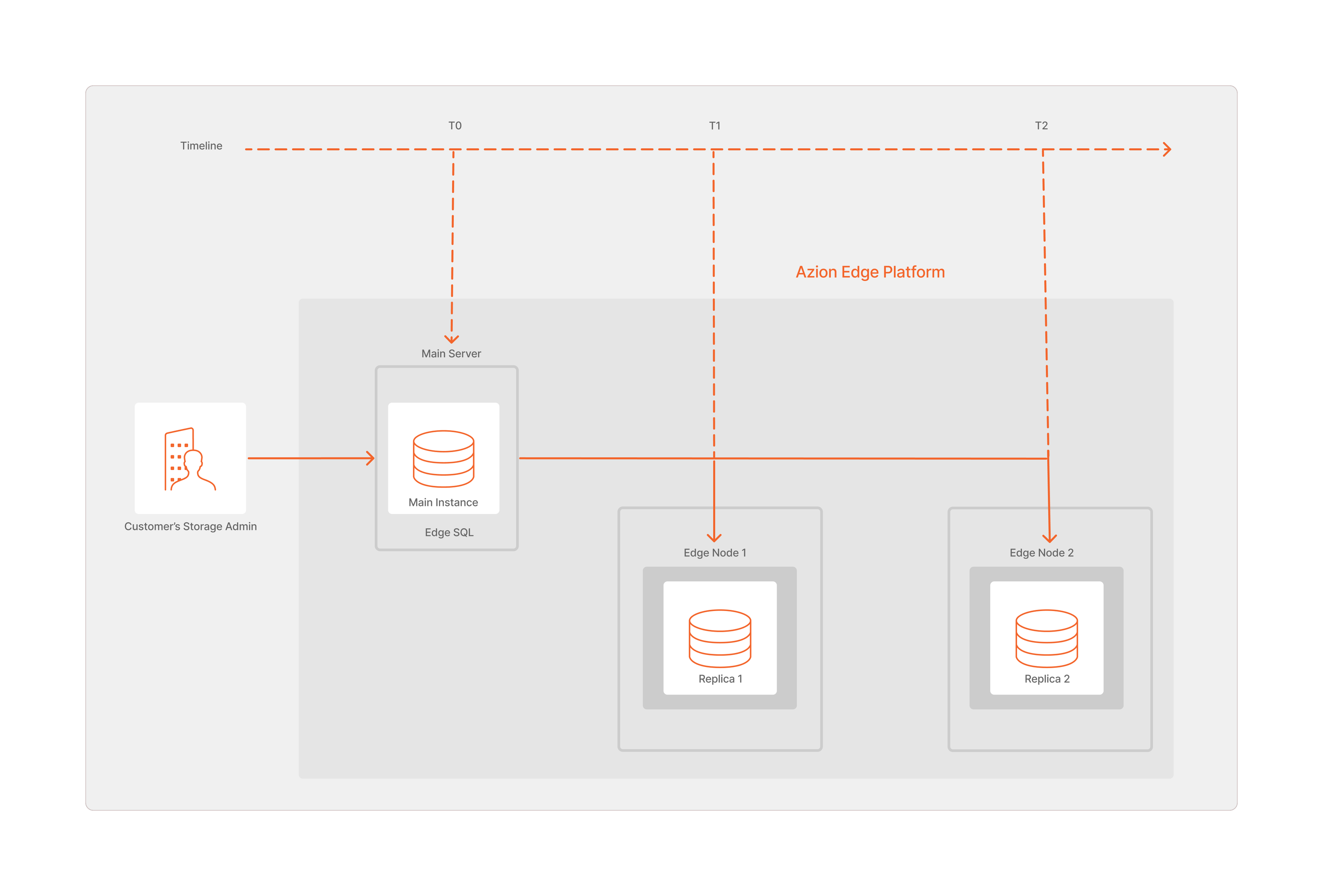
How does the Global Replication happen?
To guarantee the availability and fail tolerance of Edge SQL, the replicas are distributed within the Azion Edge Network to ensure that all information is replicated and stored across the desired nodes. This comprehensive replication strategy guarantees that data is accessible and up-to-date when users directly access it at the edge, regardless of their location.
To achieve this, the operations executed on the Main Instance database are packaged into Write-Ahead Logging (WAL) files. These WAL files, along with full snapshots, are then distributed across the edge network to ensure data availability and consistency across all edge locations.
- WAL files work as logs for the operations executed to modify the data. Each new data state is pulled to the replicas. This mechanism guarantees durability, atomicity, and availability. The distribution service delivers all increments and enables database recovery on each edge location.
- Once the WAL files are available on each edge location, the merging service ensures that the increments are merged in the correct order, performing the update of each replica.
In this context, Azion Edge Orchestrator receives the WAL files and snapshots generated from the Main Instance, executes an asynchronous read replication, and then replicates the data across the edge locations.
Since updates are asynchronous, there’s a possibility that the read replica may lag behind the current state of the Main instance. This lag, known as replica lag, represents the difference between the Main instance and a read replica. It’s important to note that multiple read replicas can exist, each potentially experiencing varying degrees of lag.
About consistency models
When a transaction is initiated on the Main Instance, the view that the transaction receives is “frozen” in time. Any write operations performed by a transaction are immediately visible to itself but completely isolated from any other ongoing transactions. This ensures that EdgeSQL provides serializable transactions, maintaining a consistent and isolated view of the database for each transaction.
Snapshot Isolation in WAL mode
Using snapshot isolation, the changes are registered in WAL files, while the operations are implemented in the order they were executed in the Main Instance. This provides a consistent and predictable view of the database for each transaction, even in the presence of concurrent modifications. The snapshots are the basis for propagating the changes to read-only replicas and promoting the distributed database’s eventual global consistency.
What about Global Eventual Consistency?
Developers and data specialists are familiar with the CAP Theorem. According to the theorem, it’s impossible to simultaneously guarantee Consistency, Availability, and Partition Tolerance in a distributed system. During the development of Edge SQL, it was a concern how to handle this situation.
Data availability and partition tolerance are guaranteed through the distributed network, read replication, orchestration, and the failover mechanism. Precisely, using WAL files and snapshot isolation helps us in this matter. WAL files ensure durability by logging changes before they are applied to the database, which aids in recovering data in case of failures while maintaining consistency. Meanwhile, snapshot isolation ensures that concurrent transactions don’t interfere with each other, thereby preserving consistency.
This makes consistency the candidate for the trade-off. However, eventual consistency was the answer for us in this topic, having the means to ensure data eventually becomes consistent across all locations.
Using Eventual Consistency as an approach, we can ensure that updates made in the Main Instance gradually replicate across edge locations, achieving consistency over time. This approach also reduces latency on read operations because data reading doesn’t rely on synchronization between replicas.
Read Committed
Read replicas only receive committed data, ensuring that data accessible via the runtime environment follows the read committed model.
Is my data secure?
Working with data, especially sensitive data, demands the highest standards and practices to guarantee data security. The way Edge SQL works and how it was conceived facilitates this task.
The global distribution of Write-Ahead Logging (WAL) files using Edge Orchestrator guarantees the use of modern data management techniques, in distributed environments such as Edge SQL. To ensure the secure distribution and integrity verification of data, sophisticated techniques are employed. These techniques include encryption protocols, digital signatures, and checksums, among others, to safeguard data during transmission and storage.
Furthermore, the guarantee of data delivery is paramount, achieved through robust data replication strategies, fault-tolerant architectures, and monitoring mechanisms. These measures collectively preserve data’s reliability, consistency, and availability across geographically dispersed locations.
By providing runtime isolation, the execution environment of the database is also secure, preventing unauthorized access and tampering with sensitive data. Runtime isolation also ensures resource isolation, preventing resource contention and denial-of-service (DoS) attacks. Each database instance runs in an isolated environment, ensuring that it has dedicated resources and cannot adversely affect other processes on the system.
Additionally, by using the Azion Edge Platform, the data is protected by the Azion Secure products, including DDoS Protection and Web Application Firewall, to increase your data security.
Edge SQL in Practice
Looking for inspiration on how to use Azion Edge SQL in practice? In a sentence: this product streamlines querying and database operations at the edge. However, we’ve already identified some use cases that our clients and the team are benefiting from, or could start implementing now that it’s available:
- Order tracking: track orders, manage delivery statuses, and provide customers with live updates.
- Fraud detection: detect and prevent fraudulent activities swiftly by analyzing real-time data with Edge SQL.
- Personalization: deliver personalized recommendations based on user behavior.
- Real-time pricing: update product prices in real-time based on market conditions.
- Resilience: minimize downtime, prevent losses, and ensure resilience in critical applications with Edge Node database replicas.
- Simplifying microservices: leverage microservices, ensuring consistency and simplifying the data layer in serverless architectures.
Azion Edge SQL is in the Preview stage. Get to know more about how to start using it in the documentation.





