

O Edge SQL da Azion foi projetado pensando nos desafios do desenvolvimento de aplicações modernas nas quais os bancos de dados relacionais são um dos componentes-chave.
Sim, sabemos disso! Consultar, processar e gerenciar dados sempre acessando a origem e sofrendo com problemas de performance causados por bancos de dados centralizados, alta latência e outros problemas relacionados.
Por isso, esse novo produto precisava atender a alguns requisitos para ser o que estávamos planejando como uma solução ideal:
- Ser fácil de aprender e usar, empregando ferramentas e linguagens com as quais os desenvolvedores estão familiarizados.
- Facilitar a implantação de dados nas edge locations, aproveitando nossa arquitetura distribuída globalmente.
- Oferecer resiliência, garantindo integridade e disponibilidade de dados.
- Minimizar o tempo de transferência e assegurar baixa latência para respostas em tempo real.
- Fornecer alta escalabilidade para diversos requisitos de armazenamento.
- E tudo isso com escalabilidade e uma replicação eficiente em recursos para garantir custo-efetividade.
Após meses de trabalho árduo, codificação e testes, estamos entusiasmados em aprofundar e compartilhar com nossa comunidade as complexidades do desenvolvimento do Edge SQL.
Conceitos básicos do Azion Edge SQL
O Edge SQL da Azion é uma solução SQL inovadora projetada para ambientes de edge computing. Ele opera diretamente no edge, aproveitando o poder dos recursos de edge computing para bancos de dados relacionais serverless. Essa abordagem permite que ele seja acessado de qualquer edge location, facilitando o processamento em tempo real e a análise de dados diretamente na rede distribuída da Azion. Consequentemente, não há necessidade de rotear consultas para um servidor centralizado, melhorando a performance e reduzindo a latência.
Ao aproveitar o dialeto SQLite, o Edge SQL da Azion oferece um ambiente familiar para os desenvolvedores consultarem e manipularem dados sem esforço. Essa abordagem se integra com sistemas existentes, capacitando os desenvolvedores a aproveitar suas capacidades de maneira eficiente.
Em nosso esforço para fornecer uma ótima experiência ao usuário, também priorizamos a criação de um fluxo de trabalho simplificado. Em um nível alto, o Edge SQL opera da seguinte maneira:
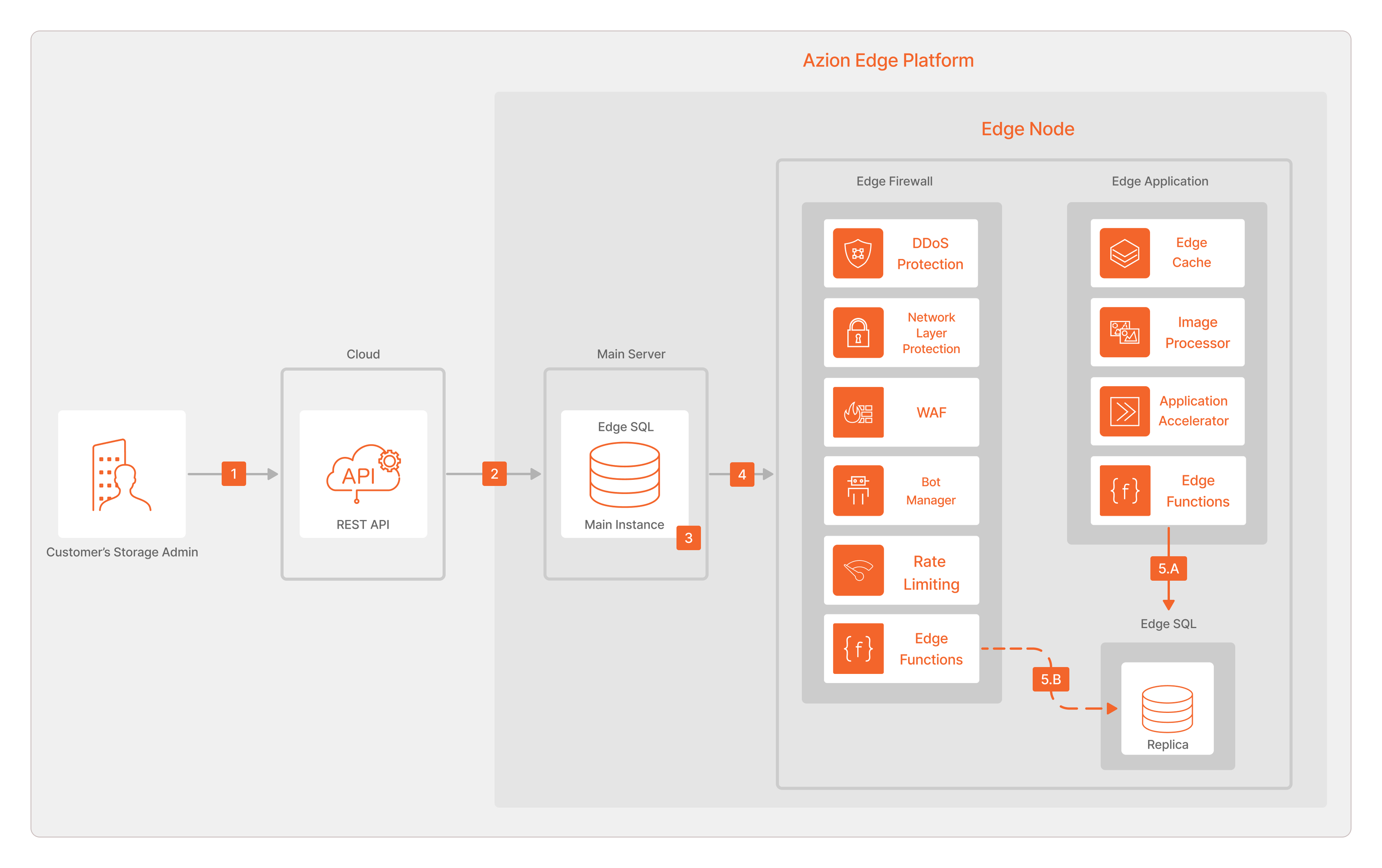
- O cliente estabelece uma conexão por meio da Azion REST API.
- As operações são automaticamente direcionadas para a Main Instance.
- A Main Instance realiza as operações e são geradas alterações incrementais.
- A replicação assíncrona de dados acontece do banco de dados da Main Instance para os Edge SQL Nodes.
- A. As Réplicas salvam as alterações de dados. Isso mantém o banco de dados atualizado, garantindo a consistência eventual. B. Também é possível salvar dados para a réplica do banco de dados do Edge SQL usando as Edge Functions do Edge Firewall.
Para entender melhor o processo, aqui está uma explicação de alguns termos chaves do Edge SQL:
- Main Instance: esta é a instância primária do banco de dados implantada no núcleo da plataforma. Ela lida com operações DDL (Data Definition Language) e DML (Data Manipulation Language) executadas pelos clientes. As atualizações do banco de dados são transformadas em snapshots incrementais, capturando as alterações feitas nos dados. Esses snapshots são então enviados para as Réplicas, garantindo que todas as edge locations tenham acesso às últimas alterações de dados.
- Edge SQL Replicas: cada edge location recebe esses snapshots incrementais e os salva em suas respectivas Edge SQL Réplicas.
- Replicação global: replicar alterações em todas as edge locations com ordem e completude garantidas em escala global é um desafio significativo. O Edge SQL aborda isso utilizando o Edge Orchestrator da Azion, que gerencia e controla eficientemente a distribuição de conteúdo entre as edge locations.
- Réplicas de leitura: nas edge locations, as alterações da Main Instance são salvas nas réplicas de leitura. Essas réplicas são disponibilizadas para leitura por meio do Cells Runtime e operam independentemente umas das outras, fornecendo um ambiente de alta disponibilidade para as aplicações. Essa independência garante que, mesmo que uma réplica encontre problemas ou fique inoperante, outras réplicas possam continuar servindo dados, minimizando interrupções.
- Além disso, essa arquitetura automatiza as tarefas de replicação, distribuindo eficientemente as atualizações e alterações de dados entre as réplicas, otimizando o uso de recursos, reduzindo o tempo de trabalho e, por fim, diminuindo os custos operacionais.
Os clientes têm duas opções para interagir com bancos de dados no ambiente Edge SQL:
- Edge SQL REST API: essa opção permite que os clientes executem queries DDL (Data Definition Language) y DML (Data Manipulation Language) diretamente em sua Main Instance. A REST API fornece uma maneira flexível e programática de interagir com o banco de dados, permitindo fácil integração em aplicações existentes.
- Edge Functions: os clientes podem acessar o banco de dados das réplicas de leitura usando uma edge function. Esse acesso somente leitura é útil quando a recuperação de dados em tempo real é necessária. As edge functions fornecem uma maneira leve e eficiente de recuperar informações do banco de dados.
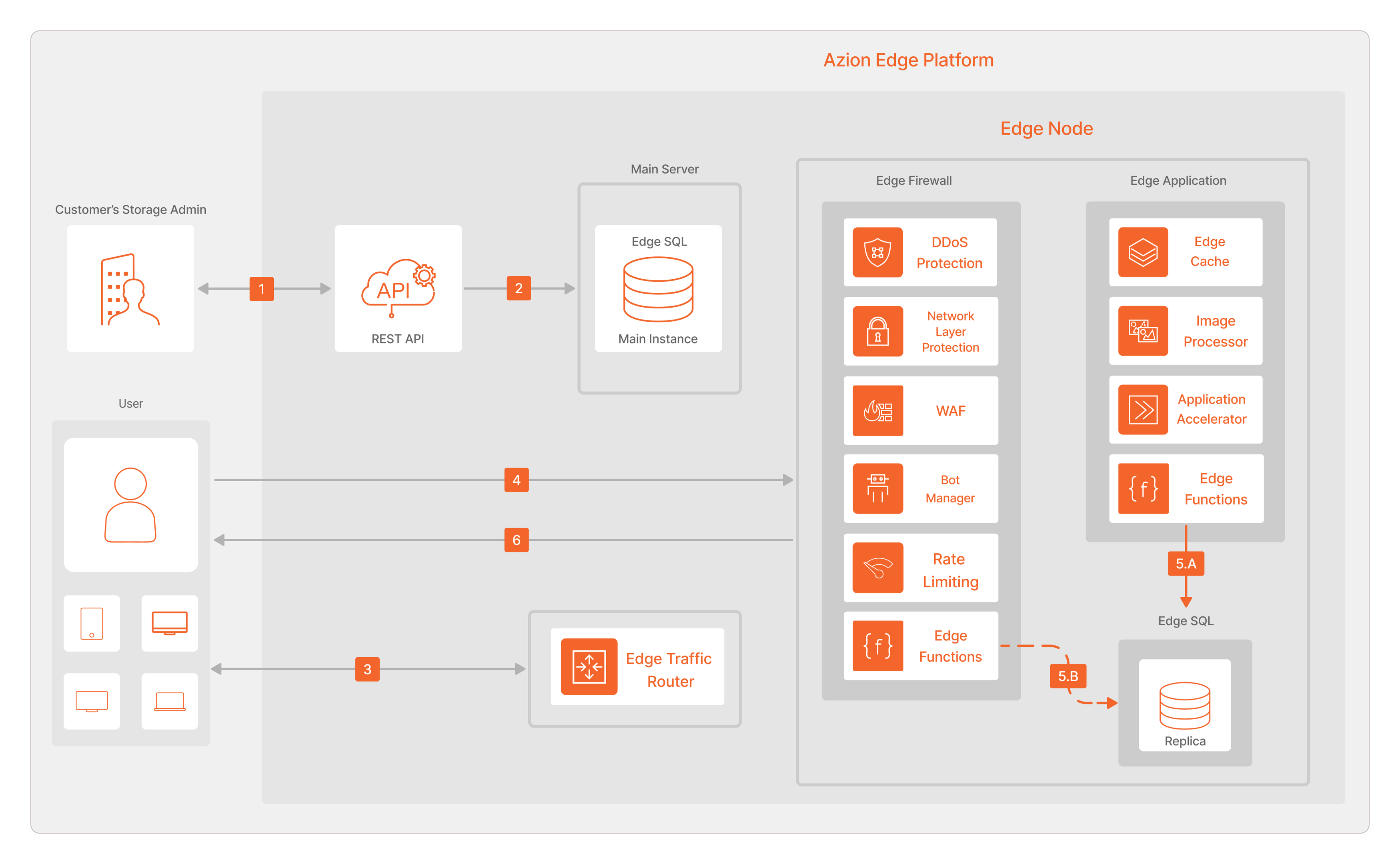
Para operações de leitura:
- O Customer’s Storage Admin inicia uma operação de leitura na Main Instance através da REST API.
- A REST API consulta os dados do banco de dados da Main Instance e retorna o resultado ao Customer’s Storage Admin.
- O usuário, através de uma application, inicia uma operação de leitura no Edge Node usando as Edge Functions. O Edge Traffic Router recebe a resolução de DNS e indica o Edge Node mais adequado a ser consultado.
- A requisição é enviada para o Edge Node mais adequado.
- A. As Edge Functions de Edge Application, em cada Edge Node, são responsáveis por ler a Réplica. B. Também é possível ler a réplica do banco de dados no Edge SQL usando as Edge Functions de Edge Firewall.
- As Edge Functions entregam o resultado da operação de leitura de volta ao usuário.
Leia mais sobre como criar tabelas e como gerenciar bancos de dados com o Edge SQL.
Por que usar Edge Functions para o Edge SQL?
O Edge Runtime da Azion fornece um conjunto de recursos para desenvolvimento em um contexto de edge, incluindo edge functions baseadas em JavaScript para implementar lógica de negócios. Então, tendo poderosas ferramentas em casa, decidimos usá-las e aproveitá-las ao máximo.
No contexto do Edge SQL, as Edge Functions da Azion podem acessar as réplicas de leitura, promovendo uma maneira de recuperar dados sem latência de rede. Essa abordagem aprimora a performance para aplicações de usuário:
- Maior throughput: ao distribuir a carga entre várias edge locations, as edge functions melhoram o throughput. Essa arquitetura distribuída garante que as solicitações por dados sejam tratadas de maneira eficiente, mesmo durante períodos de alta demanda.
- Latência ultra baixa: como não há necessidade de acessar o banco de dados de origem para operações de leitura, a recuperação de dados por meio de edge functions experimenta latência ultra baixa. Os usuários se beneficiam de tempos de resposta mais rápidos, aprimorando a experiência geral do usuário e a performance da aplicação.
Combinar o poder das Edge Functions com as réplicas de leitura oferece performance e capacidade de resposta ideais para suas aplicações, minimizando problemas de latência de rede.
O Edge SQL oferece uma API JavaScript fácil de usar para acessar bancos de dados, facilitando o rápido desenvolvimento de aplicações. Com o EdgeSQL, não há necessidade de conexões com dispositivos de rede externos para buscar dados do usuário.
Vamos explorar um exemplo de edge function para ilustrar isso:
import { Database } from "azion:sql";
const validNameRegex = /^\[a-zA-Z0-9\_\]+$/;
const supportedActions = \['list', 'head'\];
async function execQuery(dbName, query, params) {
try {
const conn = await Database.open(dbName);
const rows = await conn.query(query, params);
return rows;
} catch (error) {
throw new Error(\`Database error: ${error.message}\`);
}
}
async function handleRequest(request) {
const { pathname } = new URL(request.url);
const pathParts = pathname.split('/').filter(Boolean);
// Thorough validation
if (
pathParts.length !== 3 ||
pathParts\[0\] !== 'api' ||
!validNameRegex.test(pathParts\[1\]) || // Validate dbName
!validNameRegex.test(pathParts\[2\]) || // Validate tableName
!supportedActions.includes(pathParts\[3\]) // Validate action
) {
return new Response("Invalid request", { status: 400 });
}
const \[\_, dbName, tableName, action\] = pathParts;
let query, params;
if (action === 'count') {
query = 'SELECT COUNT(\*) FROM ?';
params = \[tableName\];
} else if (action === 'head') {
query = 'SELECT \* FROM ? limit 10';
params = \[tableName\];
} else {
return new Response("Internal server error", { status: 500 });
}
try {
console.log(\`EdgeSQL: ${dbName}, ${tableName}, ${query}, ${params}\`);
const rows = await execQuery(dbName, query, params);
if (request.headers.get('Accept') === 'application/json') {
return new Response(JSON.stringify(rows), {
headers: { 'Content-Type': 'application/json' },
});
} else {
return new Response("Only JSON format is currently supported", { status:
415 });
}
} catch (error) {
console.error(error);
return new Response("Internal server error", { status: 500 });
}
}
addEventListener("fetch", (event) =\>
event.respondWith(handleRequest(event.request)));
Este código configura uma edge function serverless para lidar com requisições HTTP para consultar um banco de dados usando Azion EdgeSQL.
- A edge function começa importando a classe de banco de dados necessária. A função
execQuerylida com a conexão do banco de dados e executa a consulta SQL, gerenciando quaisquer erros potenciais. - A função
handleRequestprocessa as reuisições recebidas, valida-as, constrói a consulta SQL apropriada e usaexecQuerypara executar a consulta. Ela retorna os resultados em formato JSON ou um erro se a requisição for inválida. - Finalmente, um
event listener for fetch eventsaciona a funçãohandleRequestem requisições HTTP.
Em resumo, esta edge function lida eficientemente com requisições HTTP para executar consultas SQL em um banco de dados EdgeSQL.
Você pode verificar a Edge SQL API para conhecer classes, métodos e atributos relacionados.
Verifique como interagir com o Edge SQL por meio de Edge Functions, Edge SQL Shelle exemplos de CURL para escrever e consultar dados.
Como a replicação global acontece?
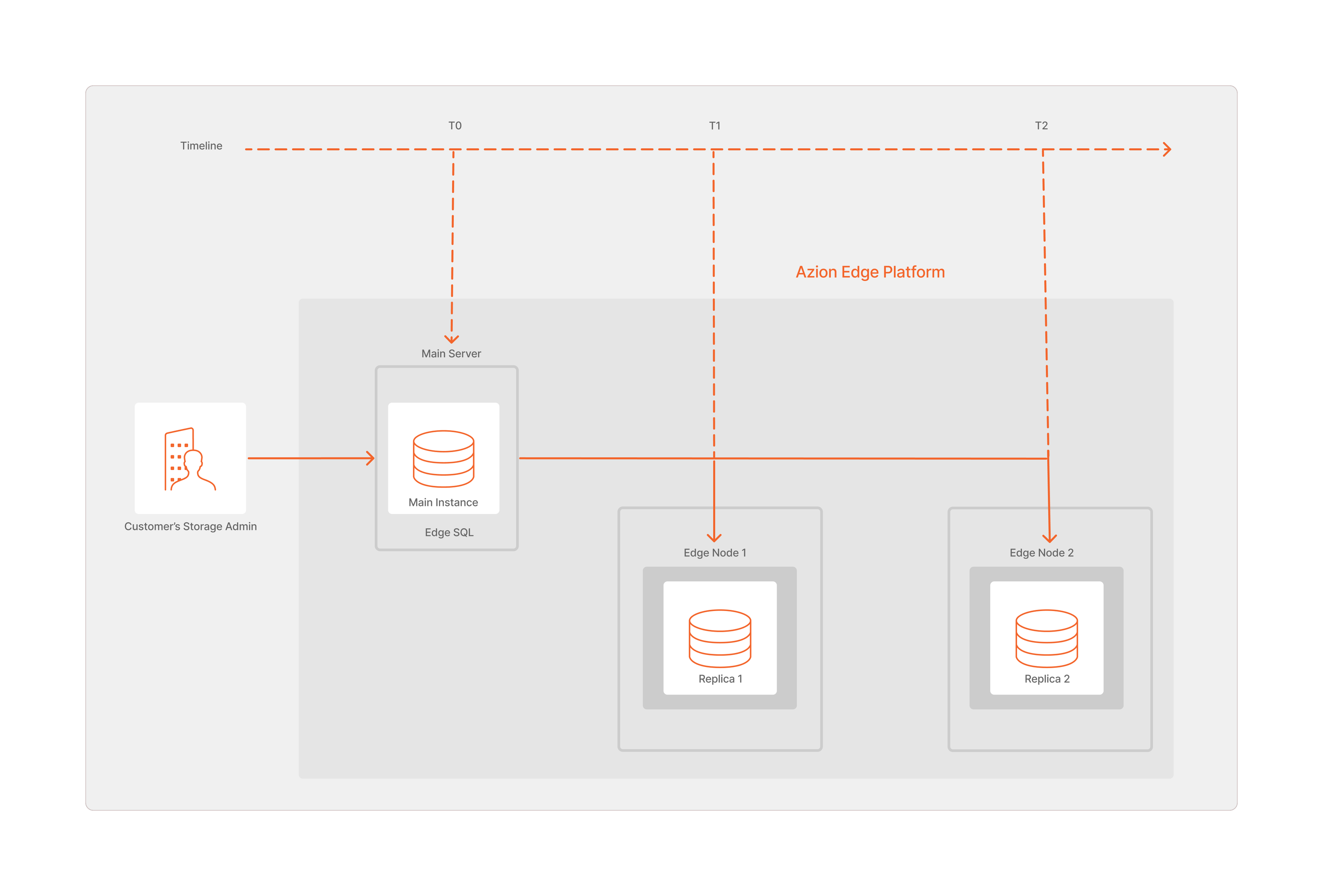
Para garantir a disponibilidade e tolerância a falhas do Edge SQL, as réplicas são distribuídas dentro da Edge Network da Azion para assegurar que todas as informações sejam replicadas e armazenadas em todos os nodes desejados. Essa estratégia abrangente de replicação garante que os dados estejam acessíveis e atualizados quando os usuários acessarem diretamente no edge, independentemente de sua localização.
Para alcançar isso, as operações executadas na Main Instance do banco de dados são empacotadas em arquivos de Write-Ahead Logging (WAL). Esses arquivos WAL, juntamente com snapshots completos, são então distribuídos pela edge network para garantir a disponibilidade e consistência dos dados em todas as edge locations.
- Os arquivos WAL funcionam como logs para as operações executadas para modificar os dados. Cada novo estado de dados é enviado para as réplicas. Esse mecanismo garante durabilidade, atomicidade e disponibilidade. O serviço de distribuição entrega todos os incrementos e permite a recuperação do banco de dados em cada edge location.
- Assim que os arquivos WAL estão disponíveis em cada edge location, o serviço de merging garante que os incrementos sejam salvos na ordem correta, realizando a atualização de cada réplica.
Nesse contexto, o Edge Orchestrator da Azion recebe os arquivos WAL e snapshots gerados a partir da Main Instance, executa uma replicação de leitura assíncrona e, em seguida, replica os dados nas edge locations.
Como as atualizações são assíncronas, existe a possibilidade de que a réplica de leitura fique atrasada em relação ao estado atual da Main Instance. Esse atraso, conhecido como atraso de réplica (replica lag), representa a diferença entre a instância principal e uma réplica de leitura. É importante notar que várias réplicas de leitura podem existir, cada uma potencialmente experimentando graus variados de atraso.
Sobre os modelos de consistência
Quando uma transação é iniciada na Main Instance, a visão que a transação recebe é “congelada” no tempo. Quaisquer operações de escrita realizadas por uma transação são imediatamente visíveis para si mesma, mas completamente isoladas de quaisquer outras transações em andamento. Isso garante que o EdgeSQL forneça transações serializáveis, mantendo uma visão consistente e isolada do banco de dados para cada transação.
Isolamento de snapshot no modo WAL
Usando o isolamento de snapshot, as alterações são registradas nos arquivos WAL, enquanto as operações são implementadas na ordem em que foram executadas na Main Instance. Isso fornece uma visão consistente e previsível do banco de dados para cada transação, mesmo na presença de modificações simultâneas. Os snapshots são a base para propagar as alterações para réplicas de leitura e promover a consistência global eventual do banco de dados distribuído.
O que é consistência global eventual?
Os desenvolvedores e especialistas em dados estão familiarizados com o Teorema CAP. De acordo com o teorema, é impossível garantir simultaneamente consistência, disponibilidade e tolerância à partição em um sistema distribuído. Durante o desenvolvimento do Edge SQL, foi uma preocupação como lidar com essa situação.
A disponibilidade e a tolerância à partição de dados são garantidas por meio da rede distribuída, replicação de leitura, orquestração e um mecanismo de failover. Precisamente, o uso de arquivos WAL e isolamento de snapshot nos ajuda nessa questão. Os arquivos WAL garantem a durabilidade registrando as alterações antes de serem aplicadas ao banco de dados, o que ajuda na recuperação de dados em caso de falhas, mantendo a consistência. Enquanto isso, o isolamento de snapshot garante que transações simultâneas não interfiram umas com as outras, preservando assim a consistência.
Isso torna a consistência a candidata ao trade-off. No entanto, a consistência eventual foi a resposta para nós neste tópico, tendo os meios para garantir que os dados eventualmente se tornem consistentes em todos os locais.
Usando a consistência eventual como abordagem, podemos garantir que as atualizações feitas na Main Instance sejam gradualmente replicadas nas edge locations, alcançando a consistência ao longo do tempo. Essa abordagem também reduz a latência nas operações de leitura, porque a leitura de dados não depende da sincronização entre réplicas.
Read Committed
As réplicas de leitura recebem apenas dados confirmados, garantindo que os dados acessíveis por meio do ambiente de runtime sigam o modelo de leitura confirmada (Read Committed).
Meus dados estão seguros?
Trabalhar com dados, especialmente dados confidenciais, exige os mais altos padrões e práticas para garantir a segurança dos dados. A maneira como o Edge SQL funciona e como foi concebido facilita essa tarefa.
A distribuição global dos arquivos Write-Ahead Logging (WAL) usando o Edge Orchestrator garante o uso de técnicas modernas de gerenciamento de dados em ambientes distribuídos, como o Edge SQL. Para garantir a distribuição segura e a verificação de integridade dos dados, são empregadas técnicas sofisticadas. Essas técnicas incluem protocolos de criptografia, assinaturas digitais e checksums, entre outras, para proteger os dados durante a transmissão e armazenamento.
Além disso, a garantia de entrega de dados é primordial, alcançada por meio de robustas estratégias de replicação de dados, arquiteturas tolerantes a falhas e mecanismos de monitoramento. Essas medidas, coletivamente, preservam a confiabilidade, consistência e disponibilidade dos dados em locais geograficamente dispersos.
Ao fornecer isolamento de runtime, o ambiente de execução do banco de dados também é seguro, prevenindo acesso não autorizado e adulteração de dados confidenciais. O isolamento de runtime também garante o isolamento de recursos, evitando contenção de recursos e ataques de negação de serviço (DoS). Cada instância de banco de dados é executada em um ambiente isolado, garantindo que tenha recursos dedicados e não possa afetar adversamente outros processos no sistema.
Além disso, ao usar a Plataforma de Edge da Azion, os dados são protegidos pelos produtos Secure da Azion, incluindo DDoS Protection e Web Application Firewall, para aumentar a segurança dos seus dados.
Edge SQL na prática
Procurando inspiração sobre como usar o Edge SQL da Azion na prática? Em uma frase: este produto agiliza a consulta e as operações de banco de dados no edge. No entanto, já identificamos alguns casos de uso dos quais nossos clientes e a equipe estão se beneficiando, ou poderiam começar a implementar agora que está disponível:
- Rastreamento de pedidos: rastreie pedidos, gerencie status de entrega e forneça atualizações em tempo real para os clientes.
- Detecção de fraudes: detecte e previna atividades fraudulentas rapidamente analisando dados em tempo real com o Edge SQL.
- Personalização: ofereça recomendações personalizadas com base no comportamento do usuário.
- Preços em tempo real: atualize os preços dos produtos em tempo real com base nas condições do mercado.
- Resiliência: minimize o tempo de inatividade, previna perdas e garanta resiliência em aplicações críticas com réplicas do banco de dados.
- Simplificação de microsserviços: aproveite os microsserviços, garantindo consistência e simplificando a camada de dados em arquiteturas serverless.
O Azion Edge SQL está disponível em Preview. Conheça mais sobre como começar a usá-lo na documentação.





